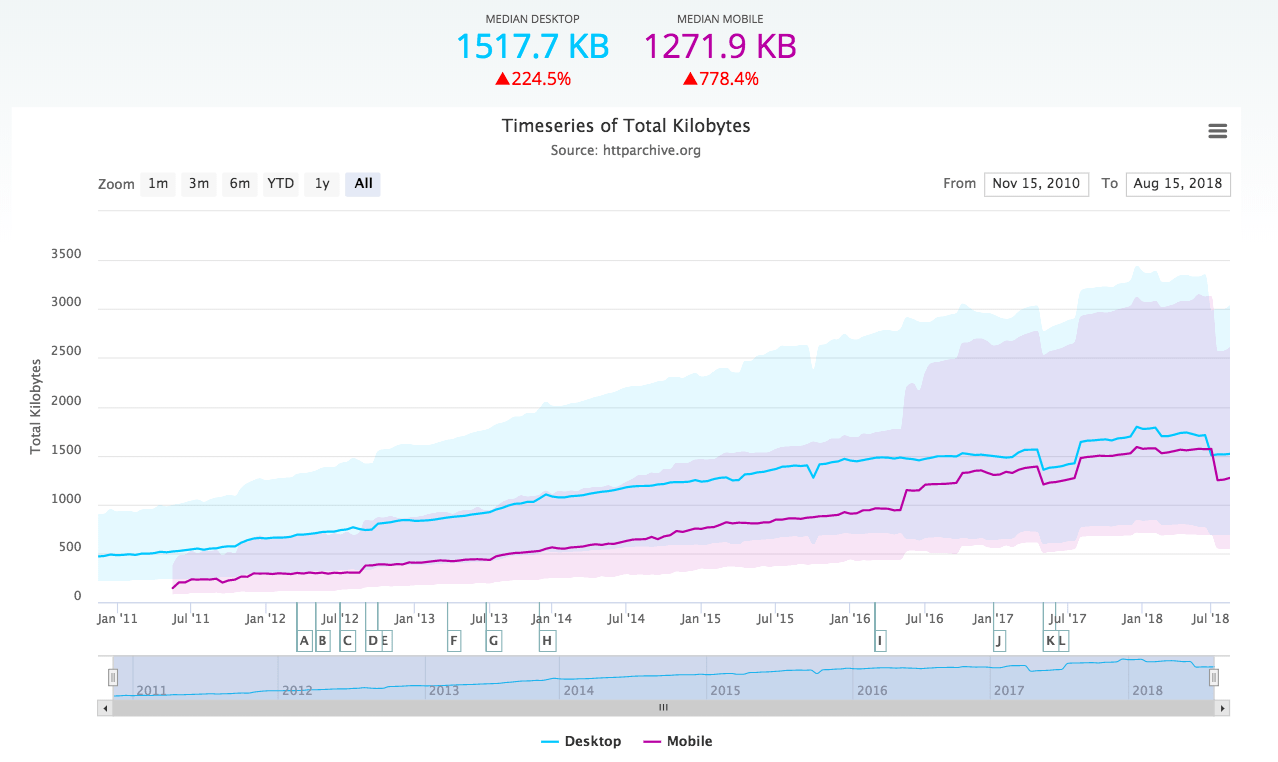

We collect a lot of data every day. In 2012, our monitoring system registered almost 65 million downtimes, we stored 106 billion monitoring results, and we handled other types of data for 300,000+ customers.
Something we’re now using for a small part of all the data we process and store each day is ZFS and its snapshot feature. So far it’s proven to be a reliable, fast, and flexible solution, and we think this is something you also would want to consider for your infrastructure.
Why we like ZFS
If you’ve ever used ZFS we’re sure you agree with us that there’s plenty to like about it. It’s simply packed with cool features, too many to mention, so here are some of the ones we find especially useful:
Data integrity – To never trust the underlying hardware was one of the stated design principles behind ZFS according to its creators. When data is generated by an application a checksum is created by ZFS. The checksum and the data are stored separately on disk, reducing the risk for both being deleted or damaged in case something would happen. Later, when data is read back, it’s validated against the checksum. If there is no match, it will then attempt to read the data from another disk in the RAID set. All in all, much of the functionality that ensures data integrity is resting with the file system rather than higher-level applications or hardware.
Capacity – What’s not to like about a filesystem that supports virtually unlimited storage? ZFS is a 128-bit file system enabling a maximum size of a single file of 16 exabytes, the equivalent of almost 17M TB.
Snapshots – In ZFS a snapshot is a ready-only copy of a file system. Think if it as an exact copy of the file system as it existed at the time the snapshot was created. At first the snapshot doesn’t take up any additional space, but as data is added or changed, it continues to reference the original data, thereby maintaining a persistent file system. The way snapshots work makes them very fast as well as efficient with storage space. ZFS snapshots can be sent over a network to other machines for backup or other purposes.
How we use ZFS to backup MySQL databases
The scenario that we’ve come the furthest with in terms of using ZFS is backing up MySQL databases. For some servers, we’ve replaced MySQL Dumps, rsync, and storage appliances with ZFS snapshots.
This has essentially made the process of backing up MySQL databases faster and less complicated.
Here’s a brief description of what we do:
-
We lock the MySQL tables and flush them thereby clearing caches and making sure the latest data is written to disk.
-
We take a snapshot of the file system with zfs snapshot.
-
We unlock the MySQL tables.
-
Finally, in most instances, we send the snapshot to another machine for offsite backups using zfs send.
In this example, we’re using few steps and commands, thereby reducing the complexity and the risk that something would go wrong. Also, the whole process usually takes only a few seconds even for many GB of data.
There’s likely more ZFS in Pingdom’s future
Our use of ZFS so far has been rather limited, but we clearly see that the sky’s the limit. We’re very happy with how ZFS has performed for us as well the functionality it offers us. Right now we’re looking into how we can use it for more applications, and we’re confident we’ll utilize it more in the future.
What’s your experience of ZFS? Are you using it for anything in particular? Let us know in the comments below.