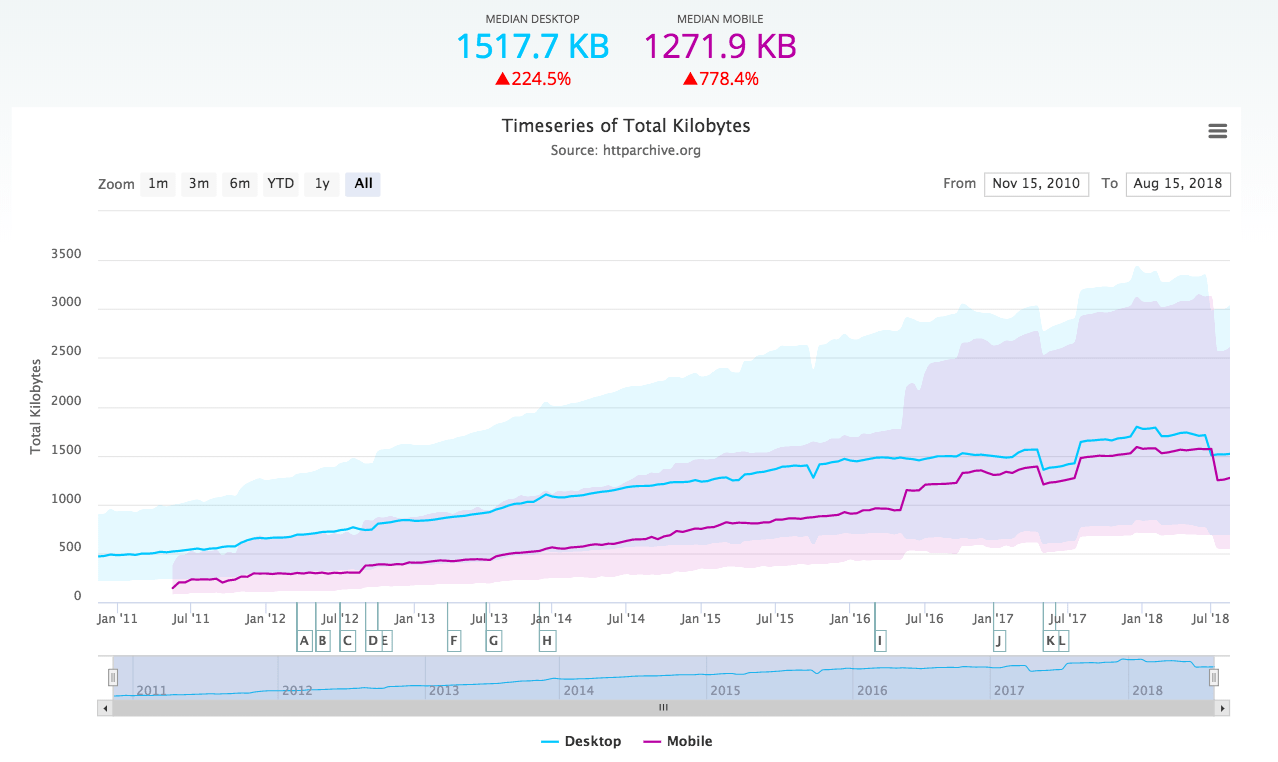

Today many of our friends are probably getting an extra shot of coffee after last night’s outage. Our live map lit up with over 100,000 outages around the world.
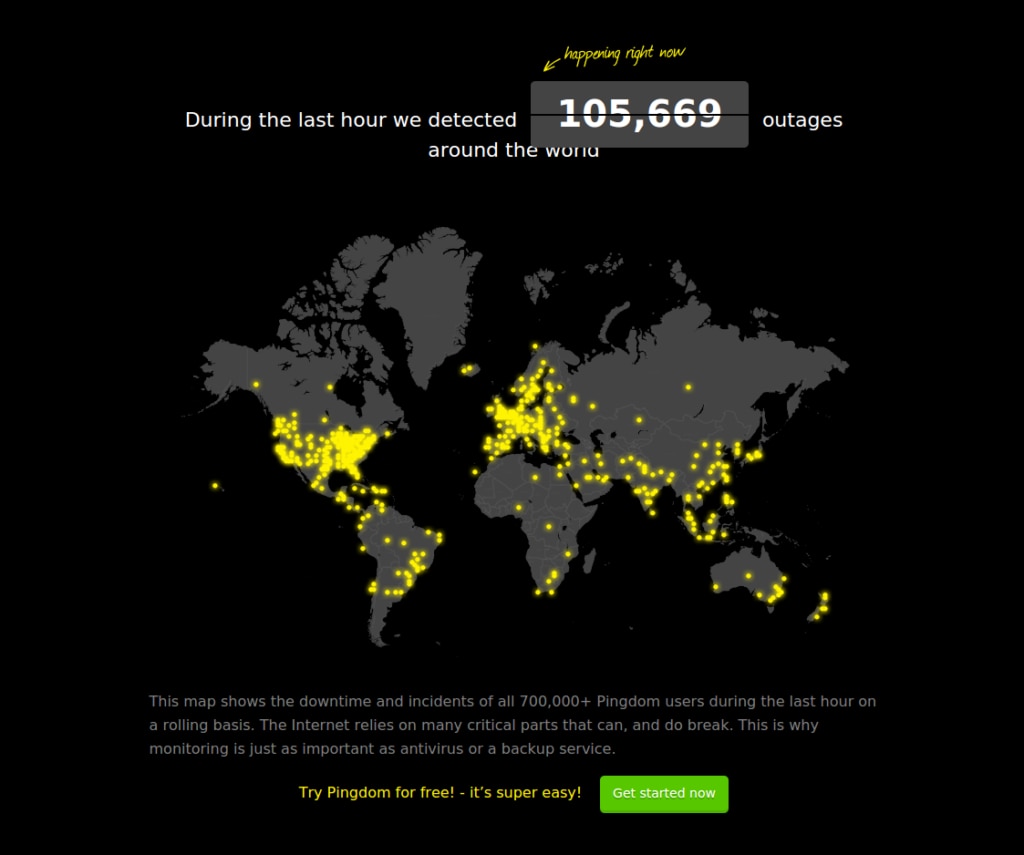
AWS had a routing problem that caused many sites to go down. The incident lasted around 40 minutes and affected Slack, Netflix, Pinterest and many others. The root cause could have something to do with a route leak, the leap second, or something else. It will probably take some time to find out for sure.
Many of our customers got alerts, many in the middle of the night, and were suspicious that they were false alarms or a problem in our systems. That is why we have a second opinion process to confirm when a site is down.
Sometimes a site appears to be up for some people but it is having problems for others. Intermittent problems are hard to spot and root cause. This is especially true when the problem is in IP routing, as it appears to be the case with this outage.
Here are the 7 things to consider in the wake of this outage:
- Evaluate the reliability of your cloud provider by the quality and detail of their communications during an outage
- Understand all the point of failure for your system: from DNS and network down to the databases powering your site
- It’s a good time to review what your monitoring strategy including not only what needs to be monitored and from which locations but also your alerts, escalations and response procedures.
- Review your user notification plans and consider setting up a public status page
- Good time to brush up on root cause identification on Pingdom and your internal systems.
- All systems fail sometimes. You need to design for failure. Don’t blame AWS.When they have an outage it is a very public event, but in reality most cloud providers have better uptime records than the majority of on-premise datacenters and they are getting better and better.
- For business-critical sites on the cloud follow multi-region or multi-cloud redundancy best practices. If you are the business owner, talk to your It team to understand their high availability and redundancy strategy.
If you don’t have testing and alerting in place yet, consider using Pingdom. Over 700K users trust Pingdom to let them know if their sites are up/down, monitor transactions, user experience, performance and incident management.
What else should web professionals think about in the aftermath of an incident like last night’s? What are your tips or best practices? Please share your opinion in the comments.