
The mighty Error 500 – Internal Error
Something very unexpected happened in March 14th this year. The public service broadcaster BBC suffered a major outage after its websites – including News, Sports and the iPlayer system – buckled in. An unknown number of people attempting to visit various online BBC services were greeted with messages such as “404 not found” or “Error 500”. With unconfirmed reports of a cyber attack, BBC staff and reporters immediately took to Twitter to broadcast what had occurred.
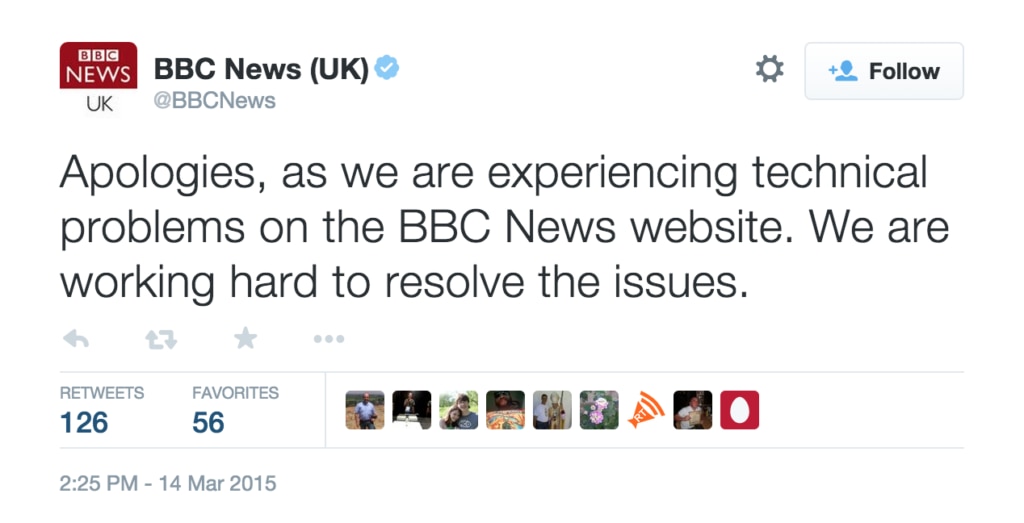
Tweet storm followed
At 06:25, the BBC News UK tweeted this: “Apologies, as we are experiencing technical problems on the BBC News website. We are working hard to resolve the issues.” BBC technology reporter Dave Lee tweeted that the problem also affected the BBC’s internal systems. Of course, the storm of mean tweets followed and it’s clear that the need for uptime isn’t just about the ability to deliver your service. It’s also about saving face.

Five hours to full recovery
Engineers worked hard to fix issues and return the website to its previous state. The networking issues left the BBC’s online services completely inaccessible for what must have been the longest hour in some BBC employees lives. And it took over five hours to fully recover.
“Our systems are designed to be sufficiently resilient (multiple systems and multiple data centers) to make an outage like this extremely unlikely”, said Richard Cooper, Controller Digital Distribution & Operations. “However, I’m afraid that last night we suffered multiple failures, with the result that the whole site went down.” Cooper highlighted both the aggregation of network traffic from the BBC’s hosting centers to the Internet and the announcement of routes onto the Internet that allows BBC Online to be found.
Siemens, the BBC’s IT contractor that handles its infrastructure network, remotely powered down equipment at a second Internet connection at Telehouse Docklands. This got things back up and running again. Then they isolated the core router in Telehouse Docklands and restored power to it. Once power was restored and the router was running in a satisfactory way, they reconnected to the Internet and BBC networks in a controlled manner.
Investigating the root cause of any incident is paramount
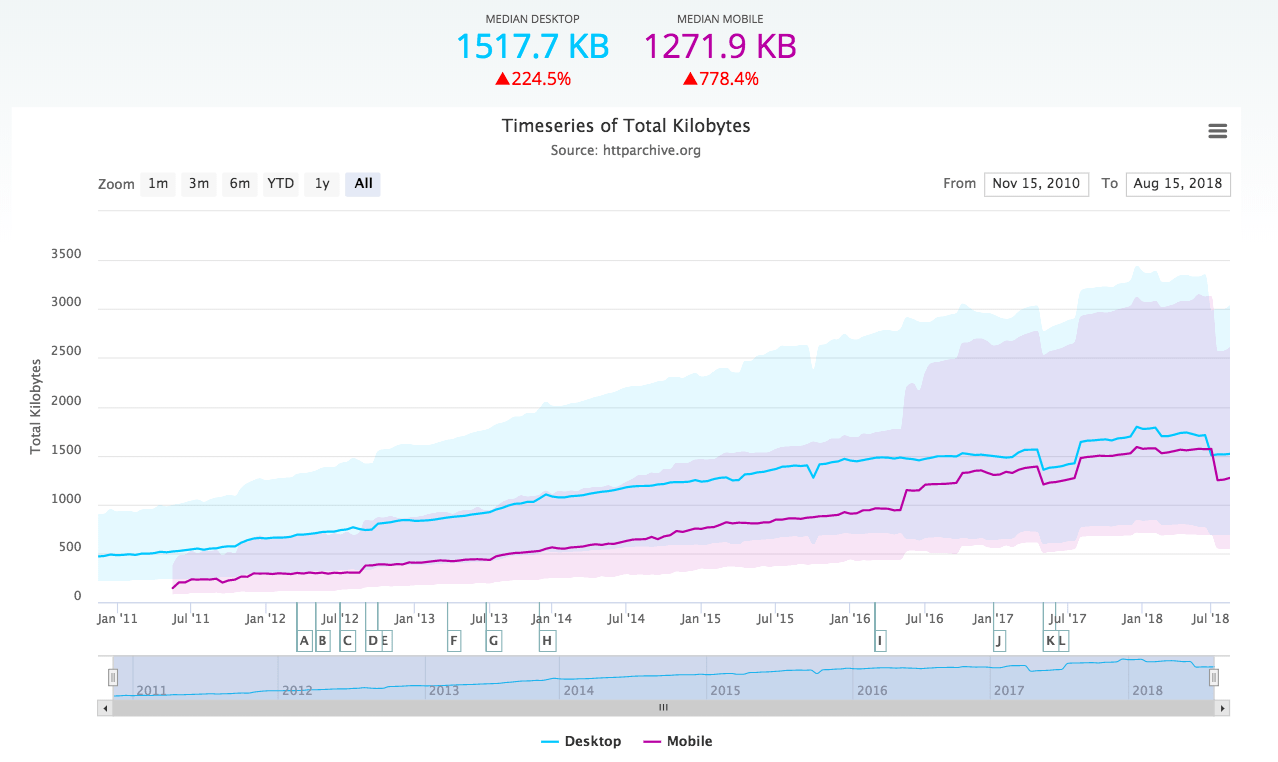
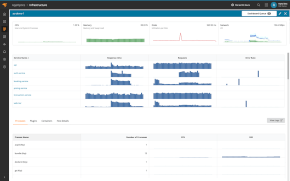
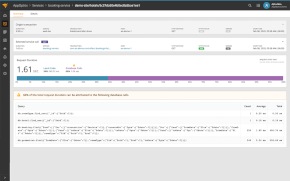
A routing issue, such as the one experienced by the BBC, affects how user requests are delivered to the website. Firstly, traffic isn’t being adequately routed from your hosting servers to the rest of the Internet. Secondly, DNS servers becomes affected, meaning the link between your website and its domains isn’t performing as they should. The critical part of any company’s infrastructure, the traffic managers responsible for handling all requests to the site and routing those requests to the right servers, should of course be designed to be highly reliable. You can, of course, also rely on Pingdom.
“The need for uptime isn’t just about the ability to deliver your service. It’s also about saving face.”
Pingdom’s probe servers connect to your site or server from outside your local network. When one of our probe servers can’t connect, another probe server will automatically try to make the same connection to get a second opinion. Your check will only be marked as confirmed down if the second test also fails. That presents you with two different trace routes to compare. You can track all network hops between our probe servers and the website that you monitor, so you can identify any problems with your hosting provider. The Root Cause Analysis helps you to find out what caused any outage. You get detailed information when the outage occurred and what triggered the analysis. For instance, you’ll find out if there’s a status code error, network congestion or slow load time.
Faulty switch?
It’s still unclear if the BBC’s problem was an internal technical inaccuracy or the result of a Distributed Denial of Service attack. Further investigations are ongoing to identify the root cause of this fault.